Apache Flink 是一个开源的分布式流处理框架,以其高效、可扩展和准确的计算能力在实时数据处理领域中占据重要地位。Flink 不仅支持批处理,还特别强调对流数据处理的优化,具有高吞吐量、低延迟、精确一次性处理语义等特点,适用于大规模数据流处理和实时分析场景。本文将深入探讨 Flink 的架构原理、关键特性以及广泛的应用场景。
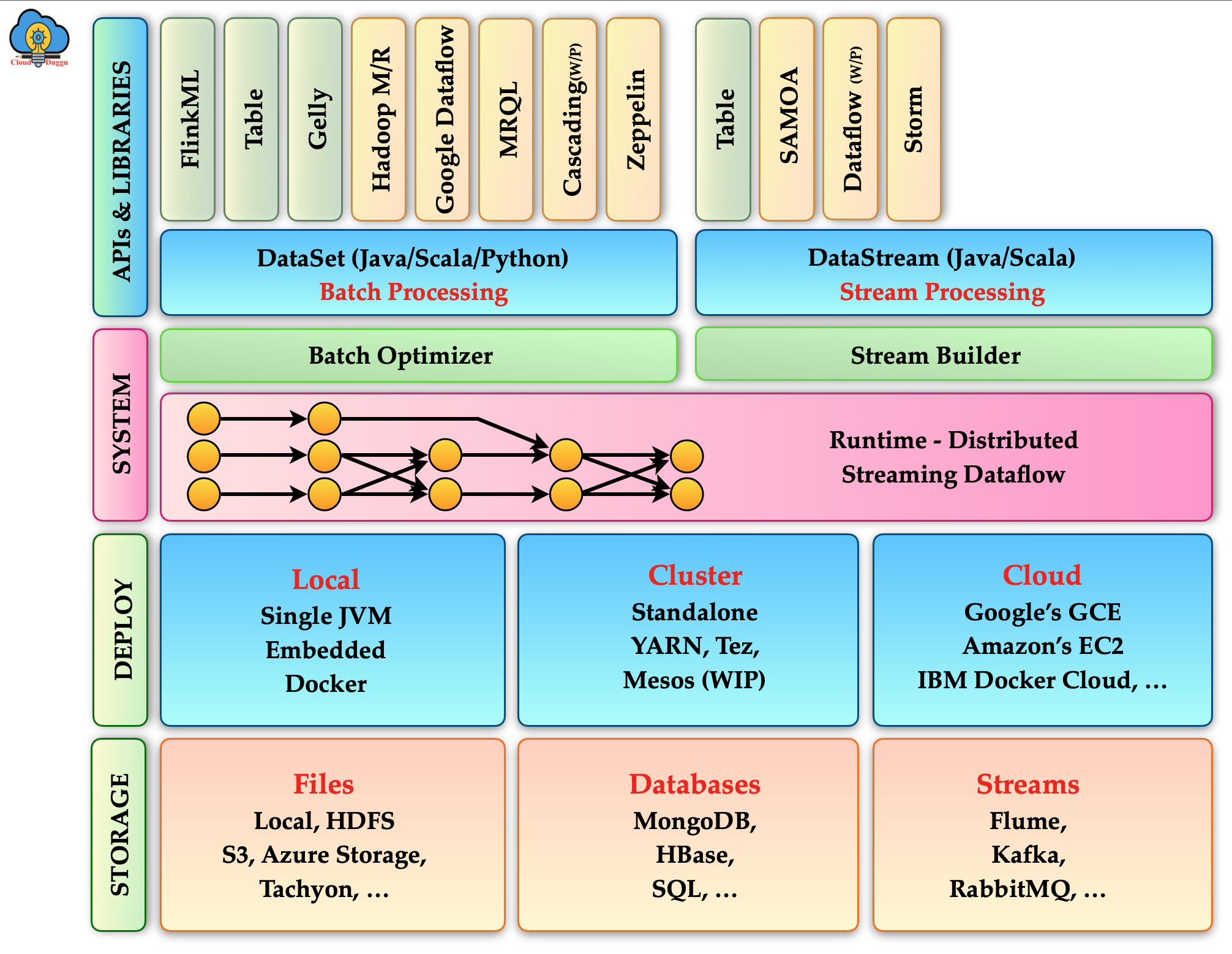
架构原理
- 流处理与批处理统一
Flink 的核心思想是将流处理(Streaming)和批处理(Batch)统一为一个引擎处理,即流与批在Flink中都是数据流(DataStream)。这种设计使得批处理可以看作是有界流处理,而流处理则可以处理无界数据流。 - 分布式数据流执行引擎
Flink 架构中的关键组件是任务管理器(TaskManager)和作业管理器(JobManager)。任务管理器负责执行并行的数据流任务,作业管理器负责接收程序、生成执行图,并协调任务执行。 - 事件驱动的流处理模型
Flink 基于事件驱动的处理模型,支持按时间和事件进行状态管理和窗口计算,保证了处理的精确一次性(Exactly-Once)语义。 - 高可用性和容错
Flink 支持作业的自动故障恢复和状态的可持久化,通过检查点(Checkpoint)和保存点(Savepoint)来实现恢复。 - 内存管理和性能优化
Flink 使用堆外内存(Off-heap memory)管理和内存分配算法来优化性能,尽量减少垃圾回收对性能的影响。
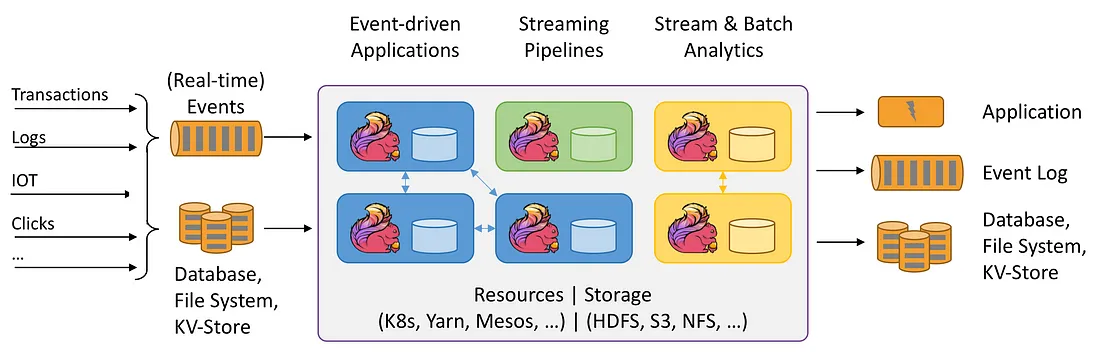
核心组件
Flink 的核心架构由多个关键组件构成,这些组件协同工作以实现高效的数据处理和任务执行:
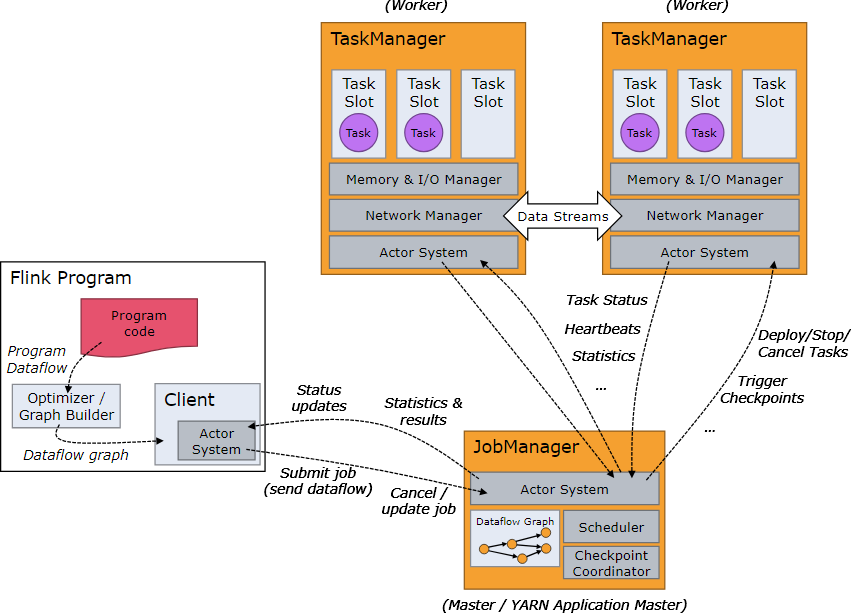
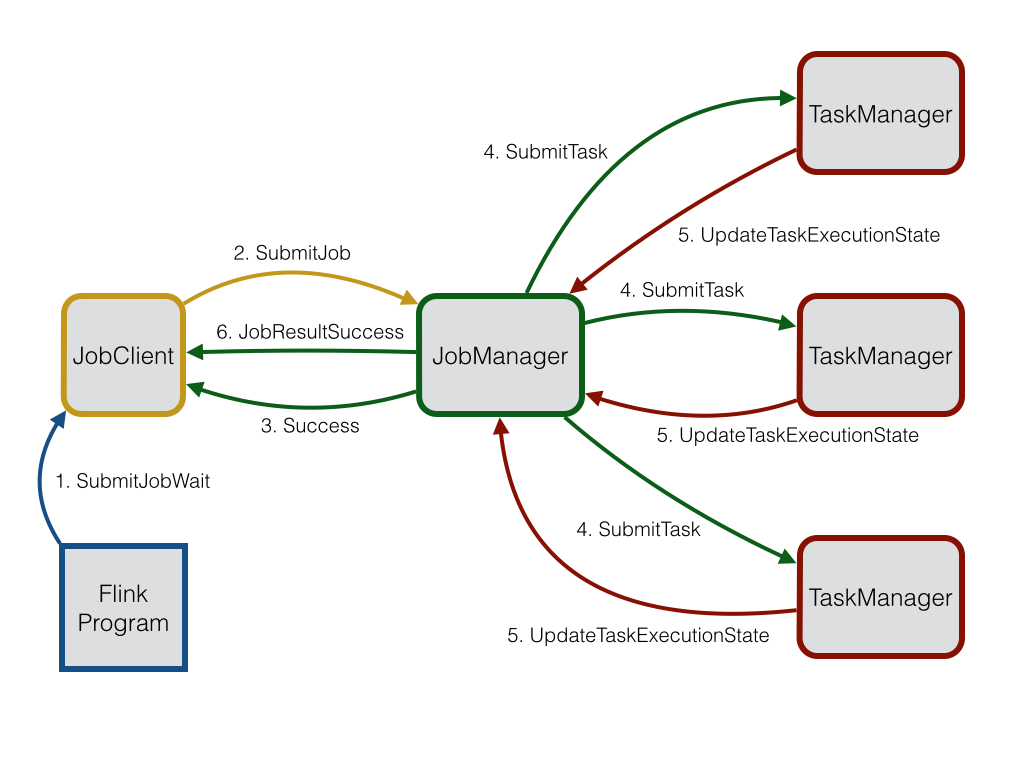
JobManager: 作为 Flink 集群的控制中心,JobManager 负责协调分布式执行。其主要职责包括任务调度、检查点(Checkpoint)管理、故障恢复以及元数据管理。JobManager 确保整个应用的顺利运行,并在发生故障时迅速恢复状态。
TaskManager: TaskManager 是实际执行数据流任务的工作节点。每个 TaskManager 包含一个或多个任务槽(Task Slot),每个任务槽可以执行一个具体的任务。TaskManager 之间通过数据交换网络进行通信,实现数据的并行处理。
Dispatcher: Dispatcher 提供 REST 接口来提交应用,并为每个提交的应用启动一个新的 JobManager。Dispatcher 还负责维护作业的执行状态,并向客户端提供作业执行的详细信息。
ResourceManager: ResourceManager 负责管理任务槽,确保资源的高效利用。它与 JobManager 和 TaskManager 协同工作,动态分配和回收资源,以适应不断变化的工作负载。
数据流编程模型
Flink 提供了两种主要的编程模型:数据流(DataStream)API 和数据集(DataSet)API。
DataStream API: 用于处理无界数据流,支持各种流处理操作,如 map、filter、reduce、join 等。DataStream API 允许开发者定义复杂的数据处理逻辑,并支持事件时间(Event Time)和处理时间(Processing Time)的处理。
DataSet API: 用于处理有界数据集,适用于批处理任务。DataSet API 提供了丰富的批处理操作,如 map、reduce、join、groupBy 等。DataSet API 通过优化算法和并行执行,实现高效的数据处理。
分布式执行
Flink 的分布式执行模型基于流式数据流图(Streaming Dataflow Graph),其中每个操作符(Operator)在不同的 TaskManager 上并行执行。这种设计使得 Flink 能够高效地处理大规模数据,并实现高吞吐和低延迟的数据处理能力。
关键特性
高吞吐与低延迟
Flink 通过优化内存管理和数据交换机制,实现了高吞吐和低延迟的数据处理能力。Flink 采用流水线数据传输模式,减少数据传输的延迟,并通过内存管理技术,确保数据在内存中的高效利用。
精确一次(Exactly-Once)语义
Flink 提供了精确一次的语义保证,通过分布式快照(Checkpoint)和状态管理机制 (State Management),确保即使在发生故障时,数据处理也能保持一致性和准确性。Flink 的 Checkpoint 机制定期对系统状态进行快照,并在故障恢复时使用这些快照恢复系统状态。状态管理机制,包括基于内存和基于外部存储的状态管理。
事件时间处理
Flink 支持事件时间(Event Time)处理,允许用户根据事件发生的时间而不是数据到达的时间来处理数据。这对于处理乱序数据和延迟数据尤为重要。Flink 通过水位线(Watermark)机制,有效地处理事件时间的乱序和延迟问题。
丰富的连接器
Flink 提供了丰富的连接器,支持与各种数据源和数据存储系统的集成,如 Kafka、HDFS、Elasticsearch、Cassandra 等。这些连接器使得 Flink 能够轻松地与现有的数据基础设施集成,实现数据的输入和输出。
应用场景
实时数据分析
Flink 广泛应用于实时数据分析场景,如实时报表、实时监控、实时推荐系统、实时风控等。通过 Flink 的高吞吐和低延迟特性,企业可以快速获取和分析实时数据,从而做出及时的业务决策。
复杂事件处理(CEP)
Flink 的复杂事件处理能力使其成为构建实时规则引擎和事件处理系统的理想选择。通过定义复杂的事件模式,Flink 可以实时检测和响应特定的事件序列,如欺诈检测、异常检测等。
实时流处理
Flink 在实时流处理领域表现出色,能够处理高并发、高吞吐的流数据。无论是日志处理、实时数据集成还是实时数据清洗,Flink 都能提供高效可靠的解决方案。
机器学习与迭代计算
Flink 的迭代计算能力使其适合用于机器学习和图计算等需要大量迭代计算的场景。通过 Flink 的批处理和流处理能力,可以高效地进行模型训练和预测,如实时推荐系统、实时分类器等。
总结
Apache Flink 作为一个强大的流处理框架,凭借其高吞吐、低延迟、精确一次语义等关键特性,在实时数据处理领域展现出巨大的潜力。无论是实时数据分析、复杂事件处理还是实时流处理,Flink 都能提供高效可靠的解决方案,满足企业对实时数据处理的需求。随着数据量的不断增长和实时数据处理需求的提升,Flink 将在未来的数据处理领域中发挥越来越重要的作用。

