Apache Parquet是一种面向列的存储格式,广泛应用于大数据处理框架中,如Apache Hadoop、Apache Spark等。它最初由Twitter和Cloudera公司合作开发,并于2013年贡献给Apache软件基金会,成为Apache顶级项目之一。Parquet的设计初衷是为了提高大数据处理的效率和性能,特别是在需要处理大量结构化数据的场景中。
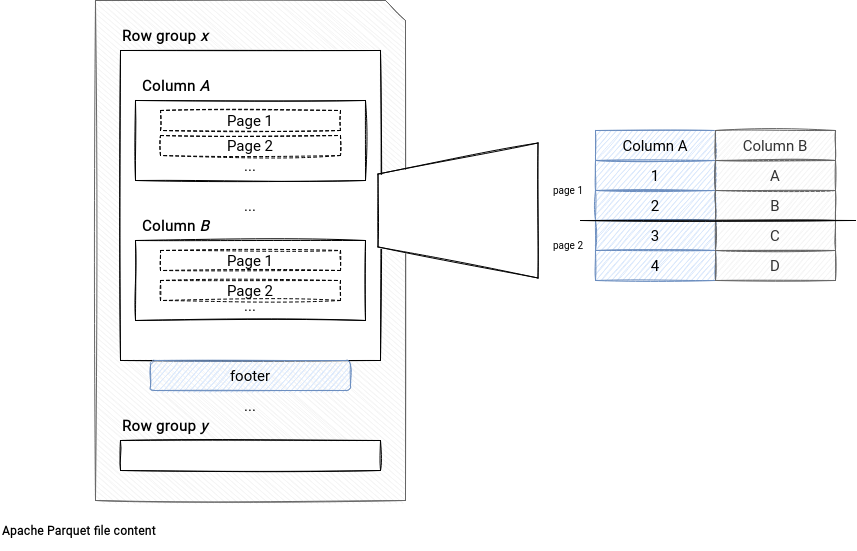
存储原理
Parquet的存储原理基于列式存储(Columnar Storage)技术。与传统的行式存储不同,列式存储将同一列的数据连续存储在磁盘上,这样可以带来以下几个优势:
压缩效率高:由于同一列的数据类型相同,可以采用更高效的压缩算法,减少存储空间占用。
查询性能优:在执行只涉及部分列的查询时,列式存储可以减少I/O操作,提高查询速度。
支持复杂数据类型:Parquet支持嵌套数据结构,可以方便地存储和查询复杂的数据类型。
Parquet文件由多个行组(Row Group)组成,每个行组包含一定数量的行。每个行组内的数据按列存储,每列数据又被分成多个数据块(Data Chunk)。此外,Parquet还使用元数据(Metadata)来描述文件的结构和数据类型,便于快速解析和查询。
使用场景
Parquet格式特别适用于以下场景:
大数据处理:在Hadoop、Spark等大数据处理框架中,Parquet可以显著提高数据读取和处理的效率。
数据仓库:在数据仓库中,经常需要对大量数据进行复杂的查询和分析,Parquet的列式存储特性可以有效提升查询性能。
数据湖:在数据湖架构中,Parquet可以作为数据存储格式,支持高效的数据存储和查询。
示例
假设我们有一个包含用户行为日志的数据集,每天产生数十亿条记录。这些日志数据包括用户ID、时间戳、操作类型、操作详情等字段。如果我们使用传统的行式存储格式(如CSV),在执行只涉及部分列的查询时,会导致大量的I/O操作,查询性能低下。
而使用Parquet格式存储这些数据,可以将同一列的数据连续存储,减少I/O操作,提高查询性能。例如,如果我们只需要查询某一天所有用户的操作类型,Parquet格式可以只读取“时间戳”和“操作类型”两列的数据,而不需要读取其他列的数据,从而显著提升查询速度。
1 | # 示例代码:使用PySpark读取Parquet文件并执行查询 |
通过上述示例代码,我们可以看到使用Parquet格式存储数据后,可以高效地执行复杂查询,提升数据处理的效率和性能。
总结
Apache Parquet作为一种高效的列式存储格式,在大数据处理领域具有广泛的应用前景。其列式存储特性可以显著提高数据压缩效率和查询性能,特别适用于大数据处理、数据仓库和数据湖等场景。通过合理使用Parquet格式,可以有效提升数据处理的效率和性能,满足日益增长的数据处理需求。

