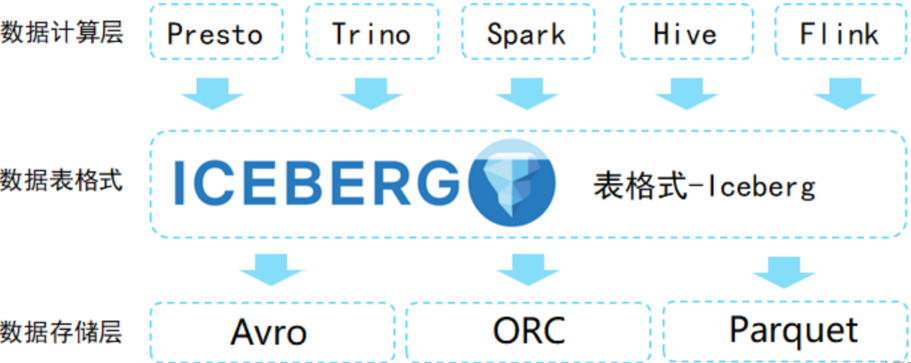
在大数据和分析不断发展的领域中,高效管理大型数据集是一个关键挑战。Apache Iceberg 作为一个强大的解决方案,彻底改变了我们处理数据湖的方式。它是一种用于大型分析表的高性能开源的表格式,旨在解决数据湖中的数据管理问题。它提供了一种新的表格式,支持高效的查询和数据管理,同时保持了数据的一致性和可靠性。Iceberg 由 Netflix 开发,后来捐赠给 Apache 软件基金会,旨在解决传统表格格式(如 Apache Hive)的一些限制。它针对现代云存储和计算环境进行了优化,提供了一系列高级特性,使得管理大规模数据集更加便捷。
工作原理
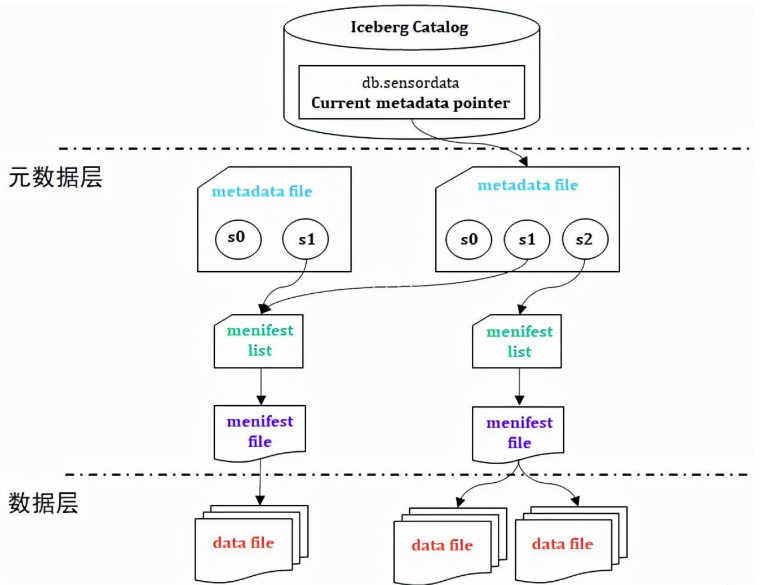
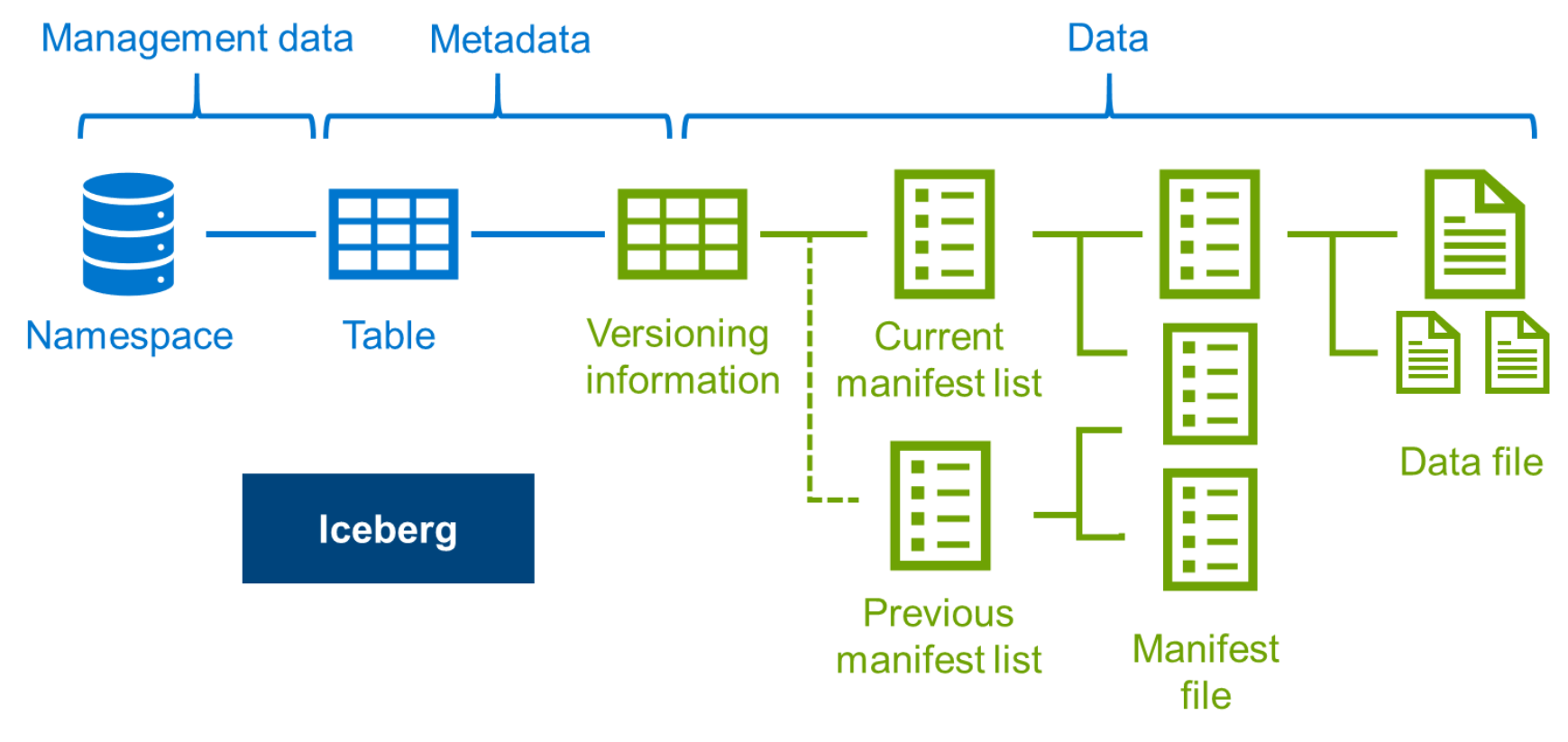
Apache Iceberg 的核心是一个表格式,它将数据组织成一系列的文件,每个文件包含一组数据记录。这些文件通过元数据文件进行管理,元数据文件记录了文件的位置、大小、统计信息等。主要分为两层:元数据层和数据存储层。Iceberg 使用一种称为“快照”的机制来管理数据的版本,每个快照代表表在某个时间点的状态。
数据组织
Iceberg 将数据组织成多个层级:
文件层:数据存储在多个文件中,每个文件包含一组记录。
清单层:清单文件即元数据文件,它记录了文件的位置和统计信息。
快照层:快照记录了表在某个时间点的状态,包括所有文件和清单文件的引用。
查询执行
当查询执行时,Iceberg 使用元数据来优化查询计划。它可以根据文件的统计信息跳过不需要的文件,从而提高查询性能。此外,green。
关键特性
模式演化:
Iceberg 支持模式演化,允许添加、删除或重命名列,而无需重写整个数据集。这种灵活性对于适应数据需求和分析需求的变化至关重要。分区:
与传统分区不同,Iceberg 使用更高效的逻辑分区方案。这意味着可以优化查询性能而无需管理多个物理分区的开销。ACID 事务:
Iceberg 通过完全支持ACID(原子性、一致性、隔离性、持久性)事务来确保数据一致性。这一特性对并发数据读写至关重要,确保所有操作都可靠一致。时间旅行:
Iceberg 提供内置的时间旅行支持,允许用户查询数据在特定时间点的状态。此功能对审计、数据恢复和历史分析非常有用。元数据处理:
Iceberg 使用高效的元数据格式,随数据集规模的增长而扩展。这种元数据管理改善了性能,减少了管理大型表格的开销。插入和删除操作:
使用 Iceberg,可以直接对表格执行插入(更新或插入)和删除操作,使得管理和更新数据变得更加简单,无需复杂的 ETL(提取、转换、加载)流程。与多种引擎的集成:
Iceberg 设计上与多种数据处理引擎(如 Apache Spark、Apache Flink 和 Trino)无缝集成。这种集成提供了选择适合分析需求的工具的灵活性。
使用场景
大规模数据分析:
当处理大型数据集时,Iceberg 的高效元数据处理和 ACID 事务确保了可靠和快速的性能。它非常适合需要对大量数据运行复杂查询和分析的用例。数据湖管理:
Iceberg 特别适合数据湖环境,其中存储着大量多样化的数据。其对模式演化和高效分区的支持使得在数据湖环境中管理和分析数据变得更加容易。实时分析:
Iceberg 能处理实时数据流,使其非常适合需要以高性能和可靠性处理、分析流数据的场景。历史数据分析:
借助内置的时间旅行功能,Iceberg 非常适合需要进行历史数据分析、审计或合规的场景。数据转换和 ETL 过程:
Iceberg 通过允许直接在表格上进行更新和删除操作,简化了数据转换和 ETL 过程,减少了复杂的数据处理工作流的需求。
如何使用 Apache Iceberg
要开始使用 Apache Iceberg,请按照以下步骤操作:
设置环境:
确保安装了兼容的大数据处理引擎,如 Apache Spark 或 Apache Flink。Iceberg 与这些引擎集成,提供无缝体验。根据处理引擎,可能需要将 Iceberg 作为依赖项添加。例如,如果您使用 Apache Spark,可以将 Iceberg 依赖项添加到 Spark 配置中。
1 | spark.conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") |
创建 Iceberg 表格:
可以通过 SQL 命令或数据处理引擎提供的 API 创建 Iceberg 表格。定义表格模式、分区和其他配置。如: spark.sql("sql statement")
1 | CREATE TABLE spark_catalog.default.iceberg_table ( |
加载数据:
使用数据处理引擎将数据加载到 Iceberg 表格中。Iceberg 支持多种数据格式,包括 Parquet 和 ORC。例如,将数据从 CSV 文件加载到 Iceberg 表格中.
1 | val df = spark.read.format("csv").option("header", "true").load("my_data.csv") |
执行操作:
一旦设置了表格并加载了数据,可以执行各种操作,如查询、更新、删除和时间旅行。
查询数据:
1 | SELECT * FROM spark_catalog.default.iceberg_table WHERE id > 100; |
更新字段名:
1 | import org.apache.iceberg.spark.Spark3Util |
时间旅行查询,查询历史时间点的数据:
1 | SELECT * FROM spark_catalog.default.iceberg_table TIMESTAMP AS OF '2024-08-01 12:00:00'; |
总结
Apache Iceberg 是一种强大的表格式,适用于管理大规模数据集和复杂的数据分析。它提供了许多高级特性,如 ACID 事务、模式演化、分区演化和时间旅行查询,使其成为数据湖和数据仓库的理想选择。通过与 Spark、Flink 和 Trino 等查询引擎的集成,Iceberg 可以提供高效的查询性能和灵活的数据管理能力。

