Kubernetes(简称为K8s)是一个开源的容器编排平台,它以自动化容器部署、扩展和操作为目标,是现代云原生应用的重要基石。我们将探讨下Kubernetes的起源、整体架构、核心组件及其工作原理,全面理解这一强大工具的作用与运作方式。
起源
Kubernetes项目最初由Google在2014年发布,并且迅速开源化。其灵感来自于Google内部的Borg系统,Borg系统用于管理Google的大规模应用程序容器化,实现了高效的资源管理和任务调度。Kubernetes的目标是提供一个开放、灵活和可移植的容器编排解决方案,使得开发者能够更轻松地部署、扩展和管理容器化应用。
Kubernetes的整体架构
Kubernetes的架构设计非常模块化和分布式,核心设计理念包括可扩展性、自动化、声明式配置和自愈能力。下图为Kubernetes的架构图:
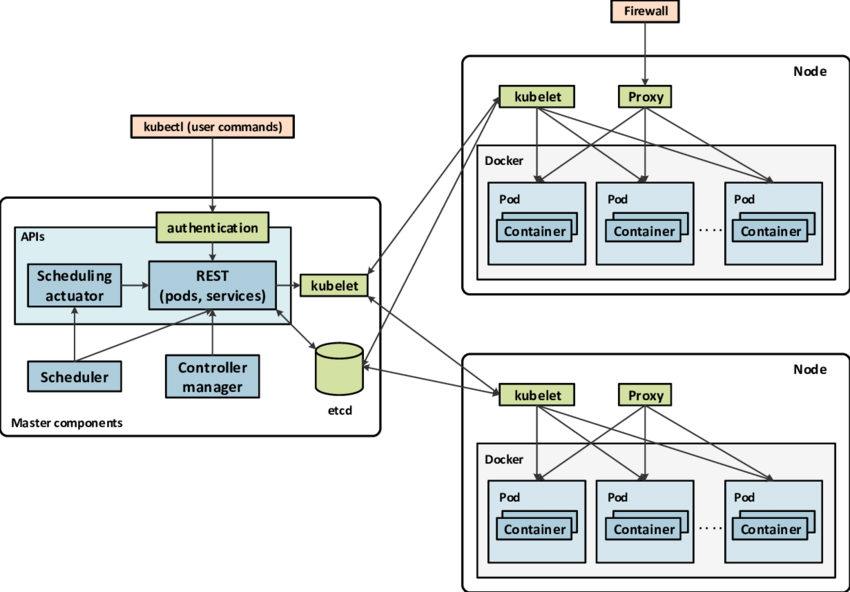
Kubernetes的主要组成部分,主要有控制平面(Control Plane)也就是Master节点和节点(Node)两大部分。
Master节点
- kube-apiserver: Kubernetes的API服务器,作为所有操作的入口,负责接收和处理来自用户或其他组件的API请求。
- kube-controller-manager: 各种控制器的集合,负责管理集群状态、节点控制和工作负载的调度。
- kube-scheduler: 负责将新创建的Pod调度到集群内的节点上,根据资源需求和约束条件选择合适的节点。
- etcd: 分布式键值存储系统,用于保存集群的状态和配置信息,作为整个Kubernetes集群的后端数据库。
节点(Node)
- kubelet: 运行在每个节点上的代理服务,负责与Master节点通信,并管理节点上的Pod生命周期。
- kube-proxy: 负责为Service提供网络代理和负载均衡服务,实现集群内部服务的访问。
除了上面的一些核心组件外,还有kubectl命令行工具、网络插件、容器运行时(如Docker、Containerd)等。
-kubectl: Kubernetes命令行工具,用于与集群进行交互。
-网络插件: 负责为Pod提供网络连接和服务发现,例如Flannel、Calico等。
-容器运行时: 负责运行和管理容器,例如Docker、Containerd等。
Kubernetes的工作原理
Kubernetes通过一系列的控制循环(control loops)和声明式API来管理和调度容器化应用。其工作原理可以简述为以下几个步骤:
定义资源对象: 用户使用Kubernetes提供的API定义应用程序的所需状态,例如
Pod、Service、Deployment等。API服务器处理请求: 所有的管理操作通过
kube-apiserver处理,kube-apiserver接收到API请求后将操作存储到etcd中,并更新集群状态。控制器管理器监控状态:
kube-controller-manager中的各种控制器(如ReplicaSet控制器、Deployment控制器)定期检查当前集群状态,确保实际状态与期望状态一致。调度器选择节点: 当有新的Pod需要调度时,
kube-scheduler根据调度算法选择合适的节点,并将Pod分配到该节点上。节点上的kubelet管理Pod: 每个节点上的
kubelet根据Master节点下发的Pod清单,通过容器运行时(如Docker、Containerd)运行和监控Pod中的容器。网络代理负责服务访问:
kube-proxy在每个节点上维护着Service和PodIP的映射关系,为Service提供集群内部负载均衡和访问。
通过这种方式,Kubernetes提供了高度自动化的容器编排能力,使得开发者可以专注于应用程序的开发和业务逻辑,而无需关心底层基础设施的管理和维护。
示例
我们可以通过一个具体的例子来演示如何在Kubernetes集群上部署两个nginx容器,并且使其可以从外部访问。
1. 创建nginx Deployment
首先,我们需要定义一个Deployment资源,用来描述nginx容器的部署和运行规则。我们指定了一个Pod模板,其中包含一个nginx容器, 并设置副本数为2,表示我们希望运行两个nginx实例。 该容器使用nginx:latest镜像,并在容器内部打开了80端口用于HTTP服务。
1 | apiVersion: apps/v1 |
2. 暴露nginx服务
接下来,我们需要创建一个Service资源来公开nginx容器,使其可以从集群外部访问。我们选择标签为”app: nginx”的Pod来提供服务。通过设置type: LoadBalancer,Kubernetes将根据云提供商的支持自动创建一个外部负载均衡器,并分配一个外部IP地址或DNS名来访问nginx服务。
1 | apiVersion: v1 |
3. Kubernetes工作流程概述
在部署nginx容器并暴露外部访问的过程中,Kubernetes的各个组件扮演了不同的角色:
- API服务器 (kube-apiserver):接收到Deployment和Service的定义请求,并将它们存储到etcd中。
- 调度器 (kube-scheduler):根据Pod的调度需求,选择合适的节点来运行nginx Pod。
- 控制器管理器 (kube-controller-manager):监控Deployment资源,确保运行着指定数量的nginx Pod副本。
- etcd:作为后端数据库存储整个集群的状态和配置信息。
- kubelet:在每个节点上运行并监控nginx Pod。
- kube-proxy:负责在集群内部实现Service的负载均衡和访问规则。
最后
Kubernetes作为现代容器编排平台的核心技术,通过其模块化的架构和强大的自动化能力,为云原生应用的部署和运维带来了革命性的变化。深入理解Kubernetes的起源、架构和工作原理,非常有助于我们开发和运维人员更好地利用这一技术,构建可靠、可扩展和高效的云原生应用。

