Overview
DuckDB is a seriously powerful database, with a host of unique and amazing features that are straight from the world of academic database research. It’s a fast in-process analytical database that can handle large datasets and perform complex queries. It’s free, open-source, and written in C++ and SQL. It supports to run on Linux, macOS, Windows, and all popular hardware architectures.
Features
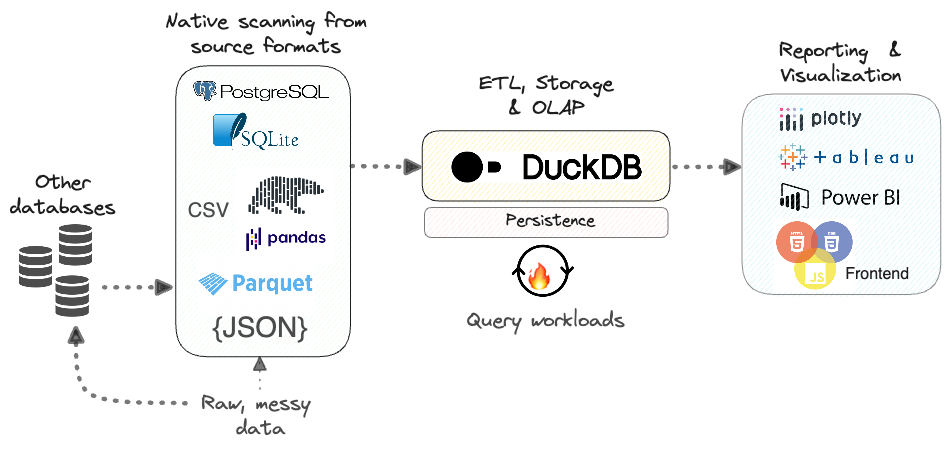
A few of key features for blazing fast OLAP query performance on large datasets (involving aggregations and joins on 100M+ rows on multiple tables), are listed below.
- Like other OLAP data warehouses, DuckDB uses
columnar storage, which is a great fit for analytical workloads, because it allows for fast, efficient scans over large amounts of data - Uses vectorized query execution, which is a technique that allows for processing large amounts of data in batches.
- Uses concurrent execution via threads, which allows for faster execution of queries, and is a great fit for modern multi-threaded CPUs.
- Offers a rich SQL dialect. It can read and write file formats such as
CSV,Excel,Parquet, andJSON, to and from thelocal file systemandremote endpointssuch as S3 buckets. - Supports integration with popular database such as
MySQL,PostgreSQL,SQLite. - Data can very easily move from a DuckDB table to a
PandasorPolarsDataFrame, andvice-versa. - It also offers connectors that allow users to directly read
Parquetdata fromAWS S3,GCSandAzure storage.
Installation
As Software
DuckDB can be installed on Linux, macOS, and Windows. It can be installed using a package manager, or by downloading the source code and building it manually. You can refer to the official documentation for installation instructions.
As Library
DuckDB not only as tools or software on system. It also supports as a library that can be used in other applications, as a part of a larger application, or as a standalone database. It can be used in Python, Node.js, R, Java, C++, and other programming languages.
Python
1 | pip install duckdb --upgrade |
Node.js
1 | npm install duckdb |
Java
1 | <dependency> |
Usage
Supports Various File Formats
For the DuckDB usage, below is using Python as an example.
1 | import duckdb |
Supports Multiple Data Sources
It also supports various data sources, including local files, S3 buckets, and remote endpoints.
1 | SELECT AVG(trip_distance) FROM 's3://yellow_tripdata_20[12]*.parquet' |
Pandas DataFrames
DuckDB can even treat pandas dataframes as DuckDB tables and query them directly.
1 | import pandas as pd |
Retional API
It also supports retional API for querying data, which allows for filtering, grouping, and aggregating data.
1 | import duckdb |
Result Output
DuckDB query result output can be saved on local file system by using below methods.
- write_csv
- write_parquet
Persistence
The data also can be persistent on disk as *.db file. The duckdb.connect(dbname) creates a connection to a persistent database. Any data written to that connection will be persisted, and can be reloaded by reconnecting to the same file, both from Python and from other DuckDB clients.
1 | import duckdb |
Or using context manager to automatically close the connection.
1 | import duckdb |
Conclusion
DuckDB is a great database for analytical workloads, with a rich SQL dialect, fast vectorized query execution, and support for various file formats. It’s also easy to use as a library in other applications, and can be used as a standalone database. Happy to try!

