在人工智能的快速发展中,如何有效地处理和生成自然语言成为了一个关键问题。近年来,RAG(Retrieval-Augmented Generation)系统的出现为这一挑战提供了新的解决方案。本文将深入探讨RAG的概念、出现的背景、原理以及其应用场景。
什么是RAG?
RAG是一种结合信息检索与生成模型的自然语言处理系统。它通过从外部知识库中检索相关信息,然后利用生成模型将这些信息整合,生成高质量的文本响应。这种方法不仅增强了生成内容的准确性,还提高了上下文的相关性。
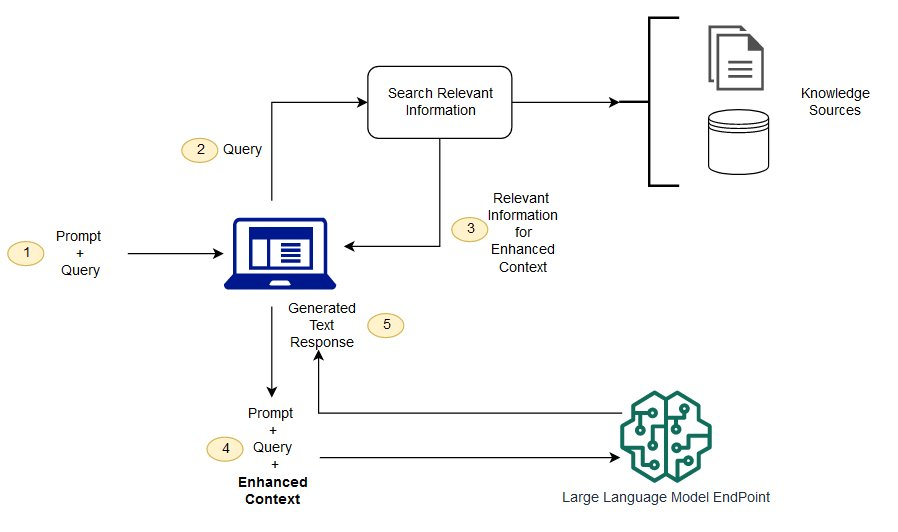
为什么会出现RAG?
传统的生成模型,如GPT系列,虽然在生成自然语言文本方面表现出色,但它们通常依赖于固定的训练数据集。这意味着它们的知识是静态的,不能自动更新。此外,当面临需要特定知识或最新信息的问题时,生成模型的回答可能会不准确或过时。
为了克服这些限制,RAG系统应运而生。它通过将生成模型与信息检索结合,使得系统能够动态访问和利用最新的信息,从而提高回答的质量和实用性。
RAG的原理
RAG系统主要包括两个核心组件:信息检索模块和生成模块。
信息检索模块:该模块负责从一个大型文档库或知识库中检索与用户查询相关的文本片段。它通常使用向量检索、关键词匹配等技术,快速定位到与查询内容最相关的信息。
向量检索:通过将文本表示为向量,计算相似度,以找到最相关的文档。常用的技术包括TF-IDF和Word Embeddings。
关键词匹配:使用关键词从数据库中筛选出相关文档,虽然效率较高,但可能不如向量检索全面。
生成模块:一旦检索到相关信息,生成模块将这些信息作为输入,结合上下文生成最终的响应。这一过程不仅保证了生成内容的流畅性和连贯性,还能融入最新的知识。生成模块利用深度学习模型(如Transformer架构)来整合检索到的信息,并生成自然流畅的文本。这一过程包括:
上下文融合:生成模型在理解检索信息的基础上,结合用户的具体问题,生成具有上下文连贯性的回答。
多样性生成:通过调整生成策略,RAG可以生成多样的响应,避免单一回答。
通过这样的组合,RAG系统能够在回答复杂问题时提供更加全面和准确的信息。
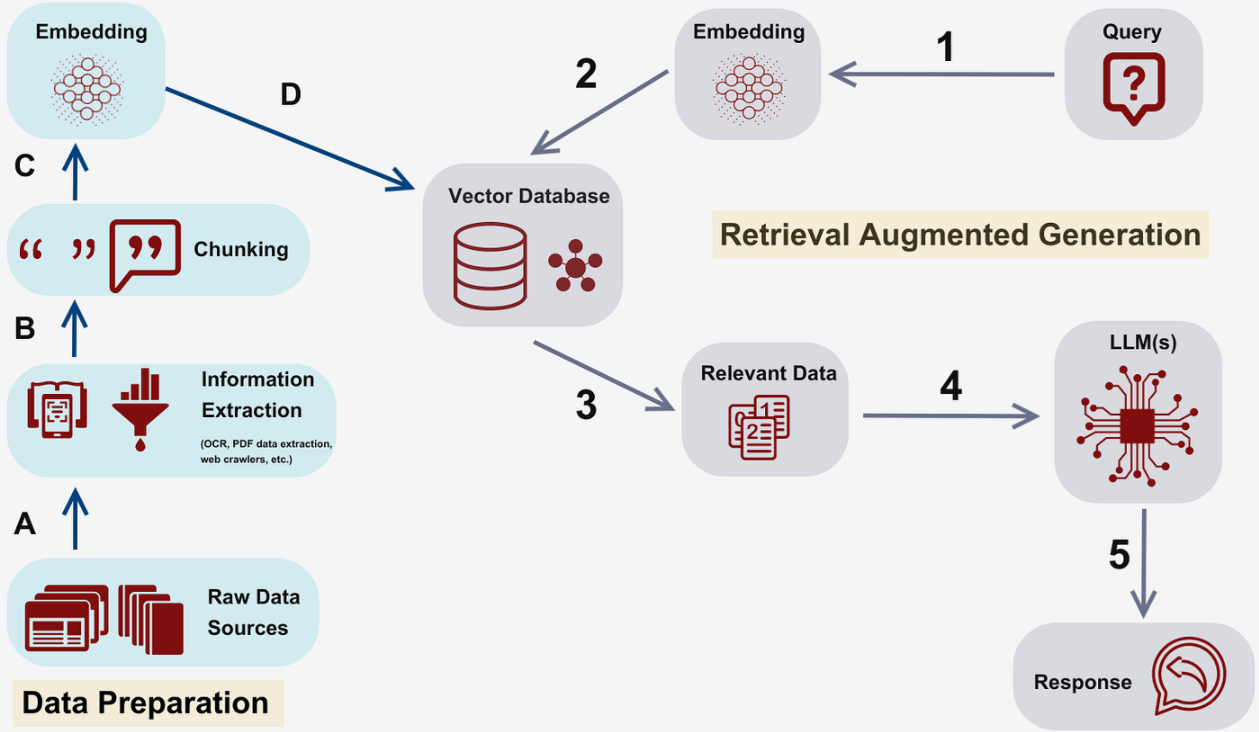
RAG的工作流程
RAG的工作流程通常包括以下几个步骤:
- 用户提出问题或请求信息。
- 系统根据用户的查询,从知识库中检索相关信息。
- 生成模块获取检索到的内容,并与上下文结合。
- 最终,系统生成并输出回答,确保信息的准确性和流畅性。
RAG的优越性
相较于传统的生成模型,RAG系统在以下几个方面具有明显的优势:
- 动态更新:RAG能够实时访问和利用最新的信息,确保生成内容的时效性。
- 准确性提升:通过检索相关信息,RAG能够提供更为准确和上下文相关的答案。
- 灵活性:可应用于多种场景,满足不同用户需求,适应性强。
RAG的应用场景
RAG系统的灵活性和高效性使其在多个领域得到了广泛应用,包括但不限于:
问答系统:在客户支持或信息查询中,RAG可以快速检索到相关文档,提供即时和准确的回答。
内容生成:在新闻报道、博客文章等内容创作中,RAG能够帮助作者整合最新的信息,生成具有深度和时效性的内容。
教育和培训:RAG可以用于在线教育平台,提供个性化的学习建议和答案,帮助学生更好地理解复杂概念。
医疗领域:在医学问答系统中,RAG可以结合最新的研究文献和指南,为患者和医生提供专业的建议。
总结
RAG作为一种新兴的自然语言处理技术,通过结合信息检索与生成模型的优势,开辟了新的应用前景。随着技术的不断进步,RAG系统将继续在多个领域发挥重要作用,推动人机交互的进一步发展。无论是解决复杂问题,还是生成高质量内容,RAG都展示了其在智能应用中的巨大潜力。

