Introduction
The App Product User Survey Feedback Sentiment Analysis Solution is a cloud-based solution that uses AWS services to analyze user feedback and sentiment of the app product. The solution uses Amazon Comprehend to perform sentiment analysis on the feedback and Amazon S3 to store the data. The solution is designed to be scalable and cost-effective, and can be easily integrated into any app product.
Basically, our survey feedback file is Excel file that contains the user feedback of app and related application info such as OS verion and app version. The feedback text is different language from global users, so we need to translate the text into English using Amazon Translate. Besides, the feedback file is generated monthly. So, the solution will extract the feedback data from the Excel file, translate the text into English using Amazon Translate, perform sentiment analysis using Amazon Comprehend, and store the data in Amazon S3. The solution will also provide a dashboard to visualize the sentiment analysis results.
The Amazon Comprehend is a natural language processing (NLP) service that can analyze text and extract insights such as sentiment, syntax, entities, and key phrases.
Solution Architecture
Below is the high-level architecture of the solution:
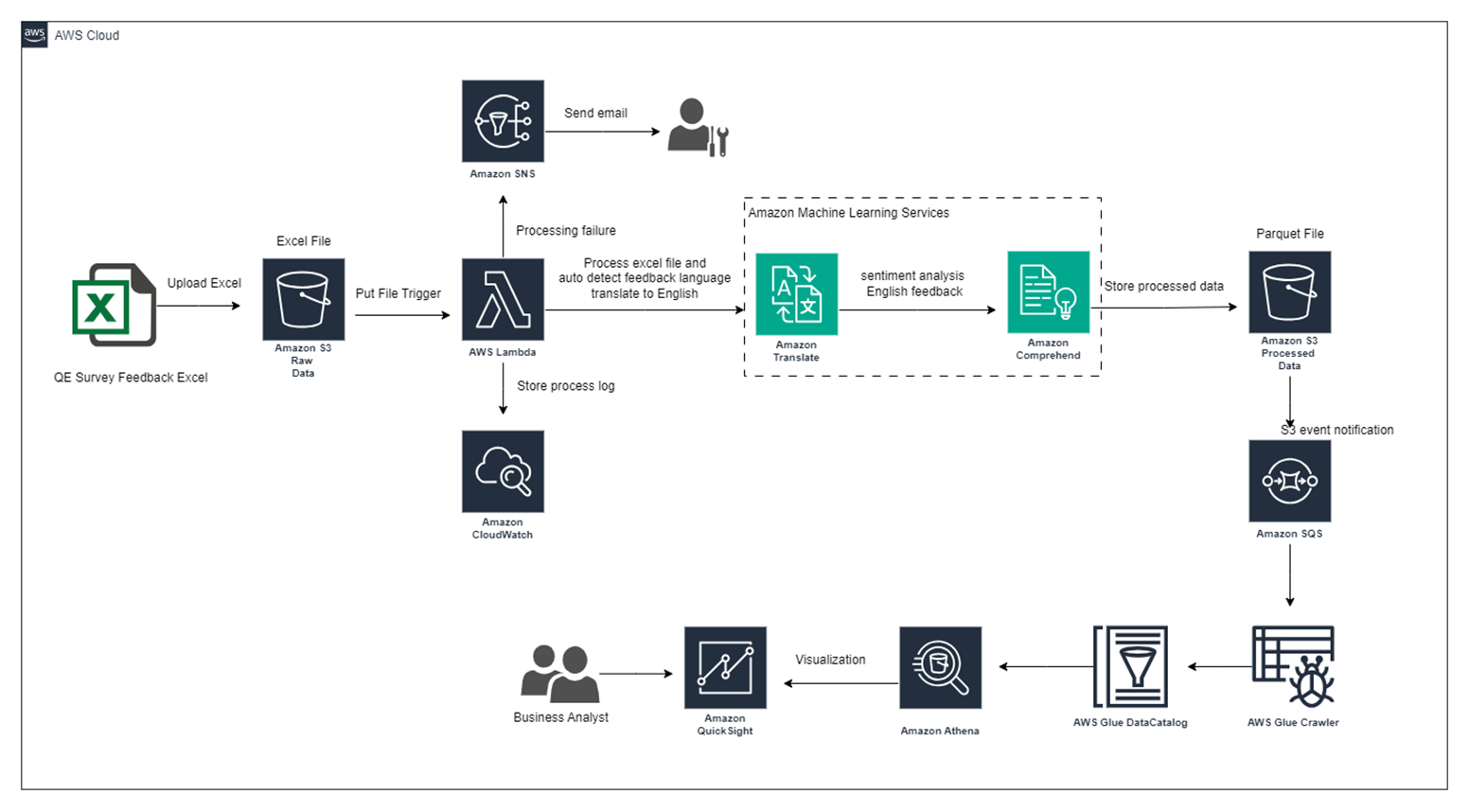
AWS Services Used
The solution uses the following AWS services:AWS S3: Amazon Simple Storage Service (S3) is a scalable object storage service that can store large amounts of data.AWS Lambda: AWS Lambda is a serverless compute service that can run code without provisioning or managing servers.AWS Comprehend: Amazon Comprehend is a natural language processing (NLP) service that can analyze text and extract insights such as sentiment, syntax, entities, and key phrases.AWS SNS: Amazon Simple Notification Service (SNS) is a messaging service that can be used to send notifications to users.AWS Translate: Amazon Translate is a machine translation service that can translate text from one language to another.AWS SQS: Amazon Simple Queue Service (SQS) is a messaging service that can be used to store and process large amounts of messages.AWS CloudWatch: Amazon CloudWatch is a monitoring service that can be used to monitor the solution and generate metrics.AWS Glue: Amazon Glue is a serverless ETL (extract, transform, and load) service that can be used to extract data from the survey feedback file and store it in Amazon S3.AWS Athena: Amazon Athena is a serverless data analytics service that can be used to query and analyze data stored in Amazon S3.AWS QuickSight: Amazon QuickSight is a business intelligence (BI) service that can be used to create visualizations and dashboards based on the sentiment analysis results.
Solution Implementation
The solution implementation is divided into the following steps:
- Create an Amazon S3 bucket as raw data bucket to store the survey feedback Excel file.
- Uploaded a survey feedback Excel file to the S3 bucket to trigger the AWS Lambda function.
- AWS Lambda to extract the survey feedback data from the Excel file, translate the text into English using Amazon Translate, sentiment analysis using Amazon Comprehend, and store the data as Parquet format in another Amazon S3 Bucket.
- Create an Amazon SNS topic to notify users by email when the Lambda process data failed.
- Create an Amazon CloudWatch to log the lamdba exeuction logs, generate metrics.
- AWS Glue Crawler to extract the parquet data from the processed amazon S3 bucket and generate a table schema.
- Using Amazon Athena to query the data from the processed Amazon S3 bucket.
- Create an Amazon QuickSight dashboard to visualize the sentiment analysis results.
The AWS Lambda core function code is as follows:
1 | import json |
The above code extracts the survey feedback data from the Excel file, translates the text into English using Amazon Translate, performs sentiment analysis using Amazon Comprehend, and stores the data as Parquet format in another Amazon S3 Bucket. also notify users by email when the Lambda process data failed by using Amazon SNS.
Below is sentiment analysis results visualization using Amazon QuickSight:
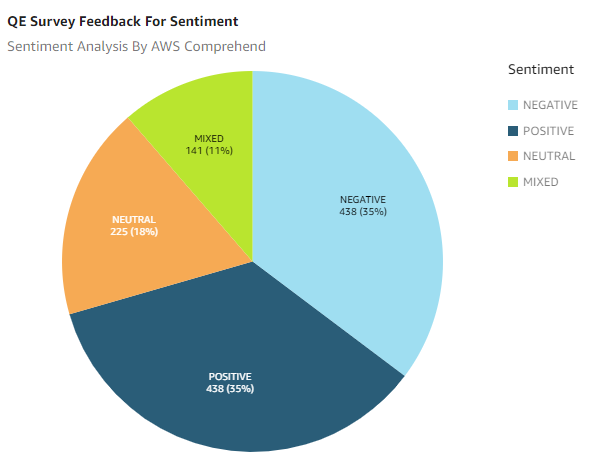
This is a high-level overview of the solution implementation. The solution can be further customized and enhanced based on the specific requirements of the app product.

