Introduction
In this article, we will build a RAG (Retrieval-Augmented Generation) chatbot using Azure OpenAI’s GPT-4 language model. We will use Python, LangChain and the Streamlit library to build the chatbot interface. Vector store will use FAISS library to store the text chunks and metadata.
What is RAG?
RAG is a technique that combines retrieval-based methods with generative models to enhance the quality and relevance of the information produced by AI systems. Here’s a breakdown of the two components:
Retrieval: The model first retrieves relevant documents, text, or data from a knowledge base, database, or external source using information retrieval techniques. This allows the model to access specialized or domain-specific knowledge, which it might not have inherently learned during training.
Generation: After retrieving relevant information, the model then uses a generative language model (like GPT-3 or GPT-4) to create a response that is coherent, contextually appropriate, and informed by the retrieved content. This allows the AI to answer questions, generate text, or assist in decision-making with enhanced accuracy and knowledge.
Technical Stack
To build the chatbot, we will use the following techiniques:
- Azure OpenAI GPT-4: We will use the GPT-4 language model from Azure OpenAI to generate responses. GPT-4 is a transformer-based language model that is capable of generating coherent and diverse text.
- LangChain: LangChain is a Python library that allows us to use the GPT-4 model from Azure OpenAI in our chatbot. LangChain provides a simple interface for building chatbots using GPT-4.
- Streamlit: We will use Streamlit to build the chatbot interface. Streamlit is a framework for building web applications in Python. It allows us to create a user-friendly interface for our chatbot.
- FAISS: FAISS (Facebook AI Similarity Search) is an open-source library developed by Facebook AI Research. It’s designed for efficient similarity search and clustering of high-dimensional data, such as vectors. The primary use case for FAISS is in applications where you need to search for the most similar items to a given query item in large datasets of vectors
Prerequisites
Before we start, make sure you have the following prerequisites:
- An Azure account
- Python 3.6 or higher
- An IDE or text editor
- A knowledge base or dataset of relevant information
Setting up the Environment
To set up the environment, we will need to install the following important libraries:
- LangChain
- Streamlit
- Azure OpenAI GPT-4
And also include the FAISS and PyPDF2 libraries. The FAISS library is used for efficient similarity search, and the PyPDF2 library is used to extract text from PDF files.
Below is the entire python libraries:
1 | streamlit==1.40.0 |
Process PDFs
Here we will read the PDF files and extract the text from them. We will use the PyPDF2 library to extract the text from the PDF files. And then save it into local vector store which can be used for similarity search by FAISS. The entire code is below:
1 | import os |
In above code, we are reading the PDF files and extracting the text from them. We are using the RecursiveCharacterTextSplitter to break the text into chunks of 1000 characters with 150 characters overlap. And then using the FAISS library to create a vector store of the text chunks. The vector store is saved in the local file system. The vector store files contains two files (*.faiss and *.pkl) which can be used for similarity search.
The *.faiss file contains the vector representation of the text chunks. The *.pkl file contains the metadata of the text chunks.
You may noticing that we are using the dotenv library to load the environment variables. You can create a .env file in the root directory of your project and add the following variables:
1 | AZURE_OPENAI_ENDPOINT=<your_endpoint_url> |
Building the Chatbot
After we have processed the PDF files and created the vector store, we can now build the chatbot using LangChain.
First, we will create a LangChain instance and load the vector store. Using FAISS.load_local method, we can load the vector store from the local file system with the same embeddings model.
1 | def embeddings(): |
Then, we will create a AzureChatOpenAI instance and load the chatbot model. We will use the AzureChatOpenAI class to interact with the GPT-4 model from Azure OpenAI. Using load_qa_chain method which is provided by LangChain, we can load the chatbot model from the Azure OpenAI.
1 | def generateChain(): |
After the chain and the vector store are loaded, we can use FAISS vector store to similarity search the user input and retrieve the most relevant document. Passing the retrieved document to the LangChain chain which loads the AzureChatOpenAI to generate the response. Below is core code:
1 | vector_store = load_vector_store(config.vector_store_folder_path, config.vector_store_index_name) |
The chain.run method takes the input documents and the question as input and returns the generated response. The match_documents variable contains the most relevant documents retrieved from the vector store. The response variable contains the generated response from the chatbot.
Finally, we will create a Streamlit interface to interact with the chatbot. We will use the streamlit library to create a user-friendly interface for our chatbot. For the streamlit library usage, you can refer to the official documentation. https://docs.streamlit.io/
1 | def main(): |
In above code, we are using the st.chat_message method to create a chat message with a specific role, using the st.chat_input method to get the user input. And using the st.spinner method to show a loading spinner while the chatbot is generating the response. Finally using the st.write_stream method to write the response to the chat message.
For the stream response, actually we mock it by using the generate_stream method. This method is used to generate the stream response. We can use the st.write_stream method to write the stream response to the chat message. This will let the chatbot to print word one by one in the chat message.
1 | def generate_stream(response): |
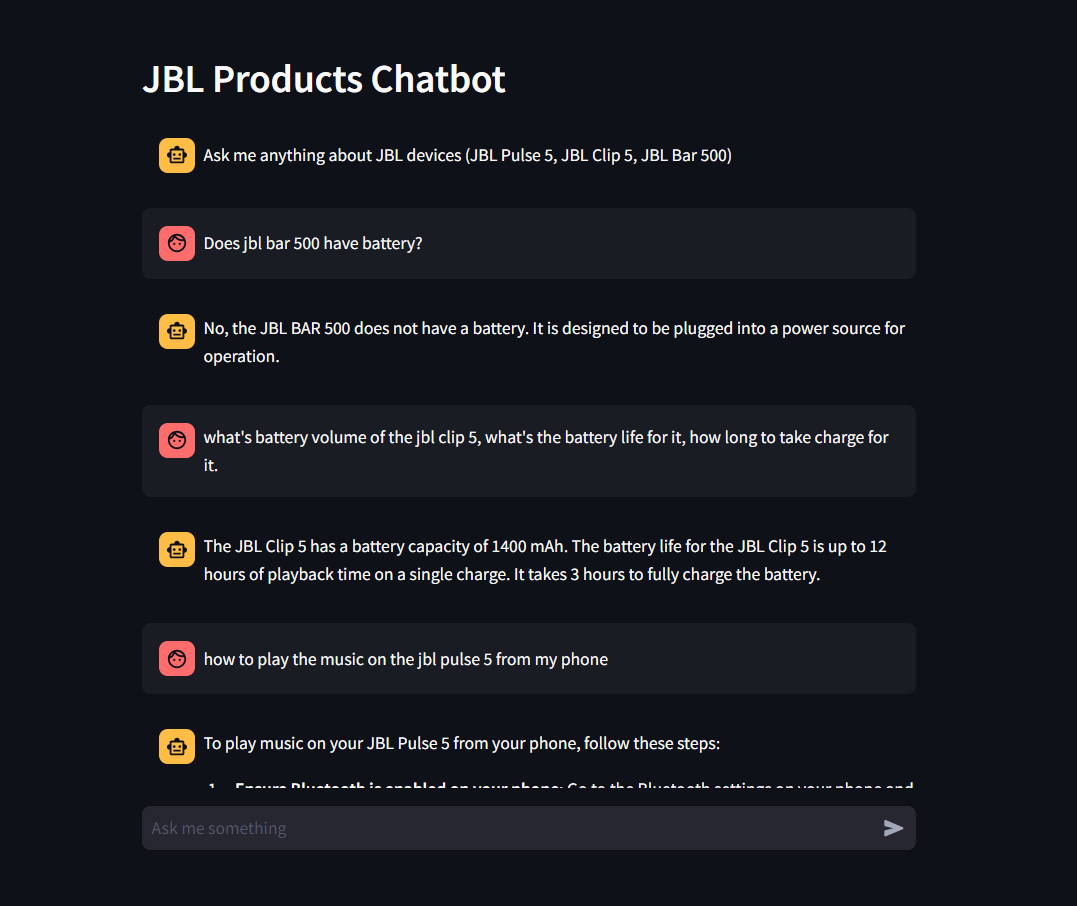
Below is chatbot conversational interface:
Conclusion
In this article, we have built a RAG (Retrieval-Augmented Generation) chatbot using Azure OpenAI’s GPT-4 language model. We have used Python, LangChain and the Streamlit library to build the chatbot interface. We have also processed the PDF files and created the vector store using FAISS library. The pdf files is crawled from the website https://www.manua.ls
For the entire code, you can refer to the Github repository: https://github.com/stonefishy/rag-chatbot. Please don’t forget to star the repository if you find it useful. Thank you for reading.

