Introduction
In this series of blogs, we will build a RAG(Retrieval-Augmented Generation) chatbot which using WiX(WiXToolset) documents as knowledge data. It will contains below steps:
- Converting PDF Document to Vector
- Building a Chatbot that can answer questions based on the documents
The technology stack used in this project are
- Python
- LangChain
- OpenAI
- Chainlit
- FAISS
In this blog, we will focus on the first step, Converting PDF Document to Vector.
Vector
The vector is a mathematical representation of a document or a text. It is a numerical representation of the text that can be used for various natural language processing tasks. The vector can be generated using various techniques like Bag-of-Words, TF-IDF, Word2Vec, etc. To store the vector, we can use various databases like FAISS, Pinecone, chroma etc.
PDF Document to Vector
FAISS
In this blog, we will use FAISS(Facebook AI Similarity Search) to save the vector on local. The FAISS is is a library for efficient similarity search and clustering of dense vectors. It is developed by Faiss Team at Facebook AI Research. FAISS is designed to handle large-scale nearest neighbor searches, which are common in applications like recommendation systems, image retrieval, and natural language processing. The library provides multiple algorithms for searching and clustering, including exact and approximate methods, and is optimized for both speed and accuracy. It supports various types of vector norms and can be used on both CPU and GPU for fast computation.
Prepare the PDF documents
For the WiX documents, we can download the documents from the official website https://docs.firegiant.com/wix/fivefour/. And here we only use the WiX upgrade guide document. Below are documents we are using:
Extracting Text from PDF Documents
We will using the library PyPDF2 to extract the text from the PDF documents. Below is code snippet to extract all the text from the PDF documents and store it in a text variable.
1 | pdf_directory = Path(pdf_storage_path) |
Embeddings
Using the AzureOpenAIEmbeddings class from langchain library to get the vector representation of the text. For the Azuer OpenAI endpoints and api keys you can define it in the .env file.
.env file
1 | AZURE_OPENAI_ENDPOINT= |
1 | embeddings = AzureOpenAIEmbeddings( |
Construct FAISS
After we have extracted the text from the PDF documents, below code snippet will construct the FAISS index. Using the RecursiveCharacterTextSplitter class from langchain library to split the text into chunks. Using AzureOpenAIEmbeddings class from langchain library, we can get the vector representation of the text. And save it into the FAISS index.
1 | text_splitter = RecursiveCharacterTextSplitter( |
So the entire workflow is that we have downloaded the PDF documents, extracted the text from the PDF documents, and constructed the FAISS index. The FAISS index will be saved in the local directory.
Below is the function code snippet:
1 | def pdfs_to_faiss(pdf_storage_path: str, index_name: str): |
There is also another way to construct the FAISS index using the langchain library from pdf documents. Using PyMuPDFLoader to load the pdf documents instead of extracting the text from the pdf documents. Below is the code snippet:
1 | def pdfs_to_faiss2(pdf_storage_path: str, index_name: str): |
Above two code snippets are reading all documents from one directory and saving them into the FAISS index. But somehow, if the text is too long and exceed the maximum length of the Azure OpenAI API, it failed to process the text. Refer to Azure OpenAI API documentation https://learn.microsoft.com/en-us/azure/ai-services/openai/quotas-limits.
We can count the token by using tiktoken library. The model is used to tokenize the text. If the model is not found, it defaults to using the ‘cl100k_base’ tokenizer. Here we can passing the AzureOpenAIEmbeddings model to the count_tokens function to count the number of tokens in the text.
1 |
|
Mergging Indexes
The FAISS supports to merge multiple indexes into one index. So we can merge the index of all the documents into one index. Below is the code snippet to merge the index of all the documents into one index.
Let’s write another function to embedding pdfs into individual index. Below function will embedding all the pdfs into individual index and save it in the specified directory.
1 | def pdfs_to_faiss_files(pdf_storage_path: str, faiss_dir_path: str): |
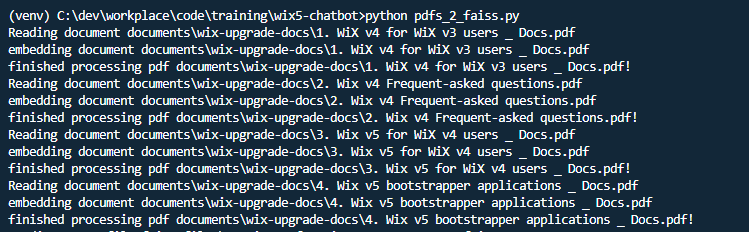
Call this function with below code snippet to embedding all the pdfs into individual index.
1 | pdfs_to_faiss_files(PDF_STORAGE_PATH, "./faiss_files") |
After these indexes are created, we can use FAISS to merge them into one index. Below is the code snippet to merge the index of all the documents into one index.
1 | """ |
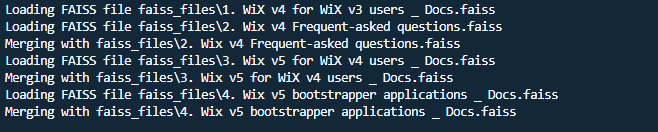
Call this function with below code snippet to merge all the indexes into one index. We merged all FAISS index files which are saved in the faiss_files directory into one index.
1 | merge_faiss_files("./faiss_files", INDEX_NAME) |

Next step, we will build a WiX chatbot which loading this FAISS index and passing the question and retrieving the relevant documents from the index. For the entire code, you can check the github GitHub repository to see the entire code.

