Today we’re going to talk about how to build a speech translator using Azure Speech Service of Azure AI . We’ll be using the JavaScript SDK for the Speech Service to build the translator. We’ll using Next.js to build the web application.
What is speech translation?
Speech translation is the process of translating speech from one language to another. It involves using speech recognition to convert the speech to text, and then using text-to-speech to convert the translated text back to speech. The Azure AI Speech provides a speech to speech translation service that can translate speech from one language to another. The Speech service supports real-time, multi-language speech to speech and speech to text translation of audio streams.
Create Azure Speech Service resource
In Microsfot Azure Cloud portal, select the Speech Service resource and go to the AI Foundry - Speech service management page.
Select Azure Speech Service
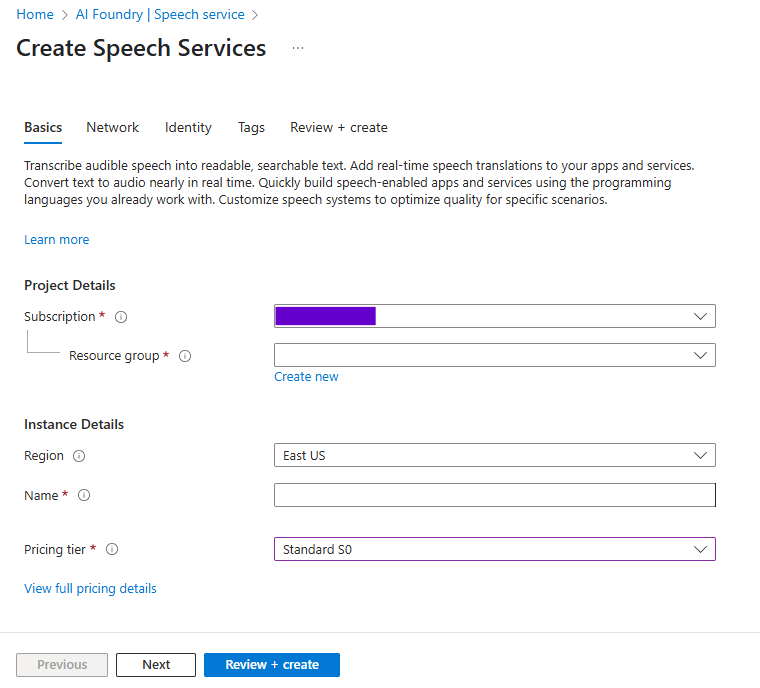
To create a new Speech Service resource is very simple, just click the Create button, and then fill the name, location, and pricing tier of the resource.
Create Azure Speech Service
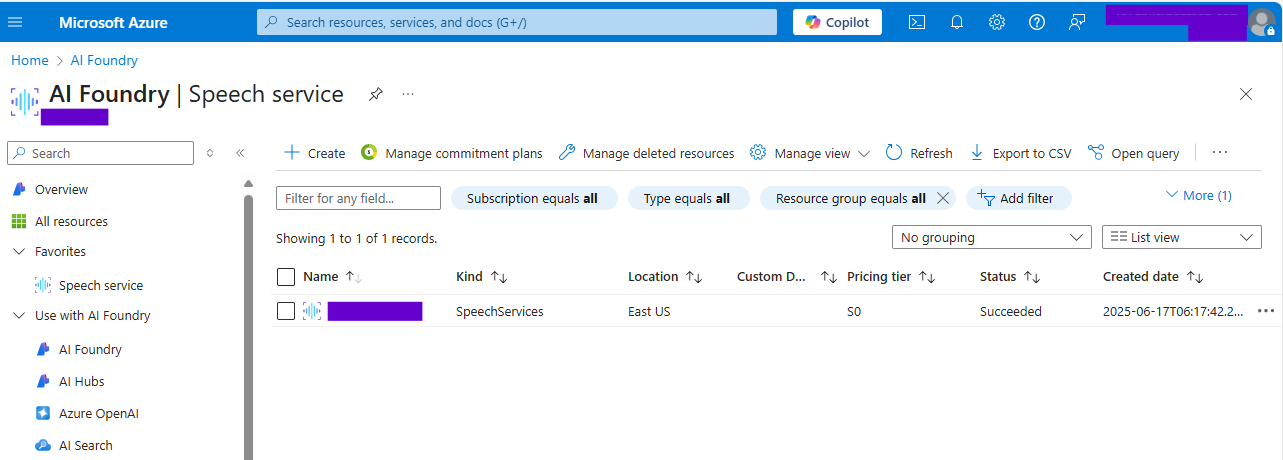
Once the speech service created, you can see it in resouce list.
Azure Speech Service List
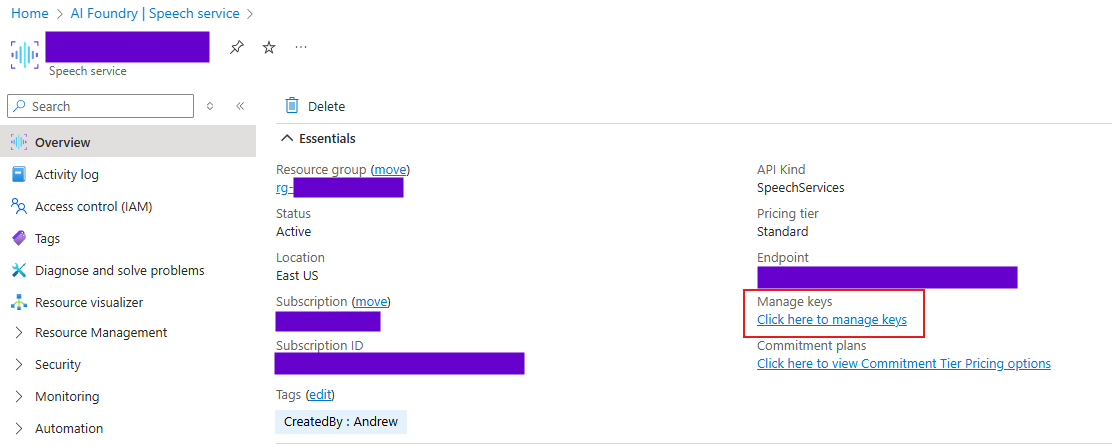
To get the key and endpoint of the speech service, click the Manage Key link, it will show the key and endpoint, location of the speech service. The subscription Key and Location will be used to access the speech service.
Azure Speech Service Key
Play the Speech Service via Speech Studio
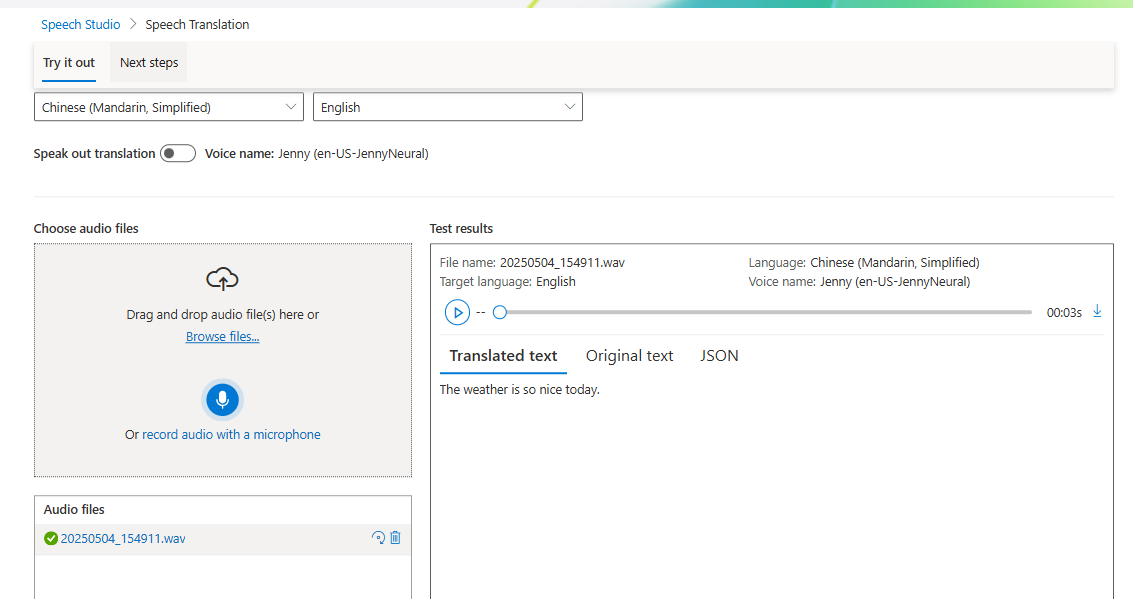
To play the speech service, you can use the Speech Studio tool. Just go to the Speech Studio page, and then click the Get Started button. Select the Speech Translation card. Let’s speech Chinese to English voice.
Azure Speech Studio - Speech Translation
Now, our speech service is ready to use.
Create Web applicaiton
To create the web application, we’ll be using Next.js framework. The Next.js is a React framework that allows us to build server-side rendered (SSR) or client-side rendered (CSR) web applications. It is a powerful framework that allows us to build fast and efficient web applications.
To create the web application, we’ll use the create-next-app command. Open the terminal and run the following command:
1
npx create-next-app@latest
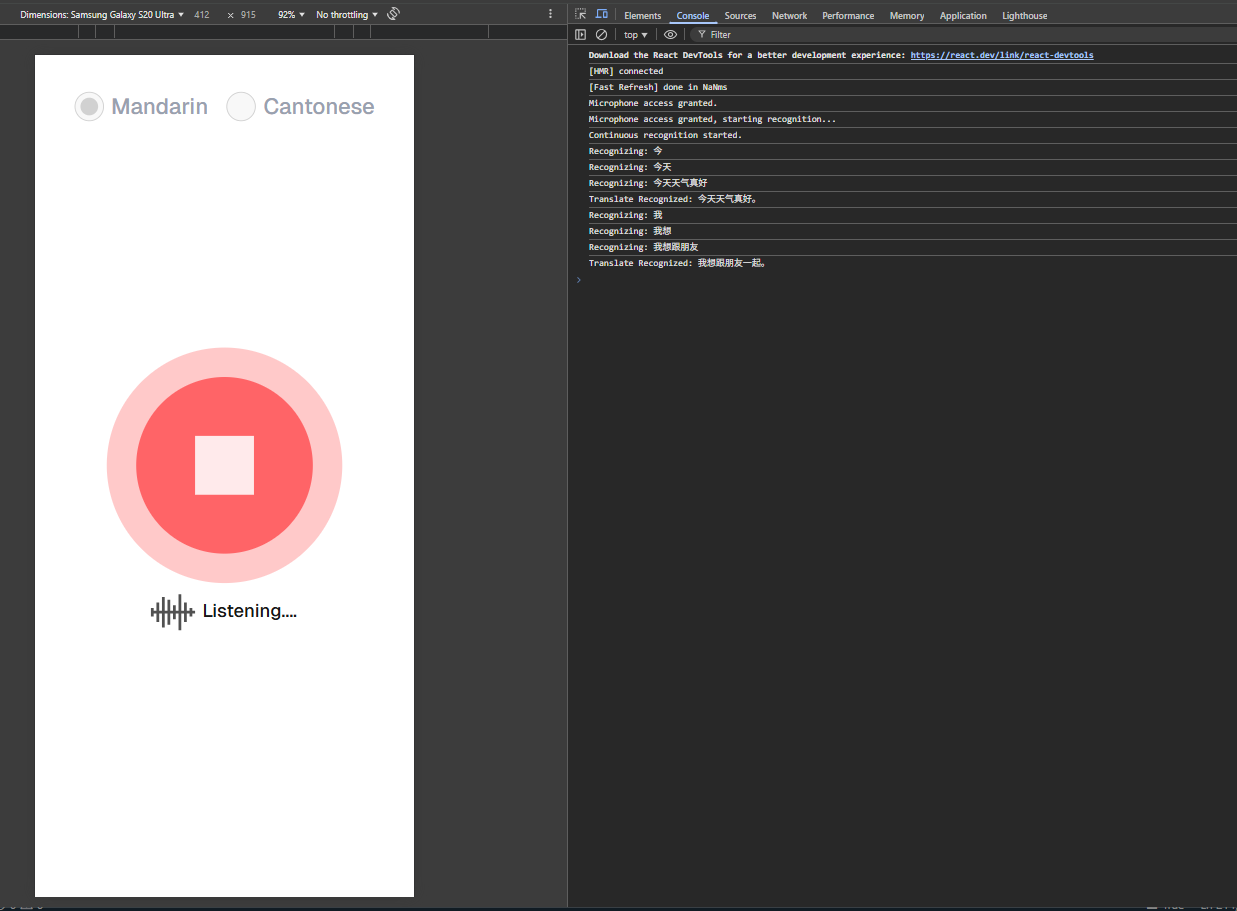
Let’s build a simple web application that user can access the device microphone and translate the Chinese (普通话), Cantonese (粤语) speech voice to English language voice in real-time. The UI of the web application will be simple and easy to use. Screenshots like below.
Speech Translator UI - Microphone
Speech Translator UI - Listening & Translation
The UI is based on the Tailwind CSS framework. The Tailwind CSS is a utility-first CSS framework that allows us to build custom user interfaces with pre-defined classes. The Tailwind CSS framework provides a set of pre-defined classes that we can use to style our web application. The Tailwind CSS framework is very flexible and allows us to build custom user interfaces with pre-defined classes. Below are the Tailwind CSS classes that we can use to style our web application.
The Azure Speech Service provides multiple language SDKs, including JavaScript, Go, C#, Python, Java, Swift, Objective-C, and C++. You can access this speech SDK link https://learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-sdk. We’ll be using the JavaScript SDK to integrate with the speech service.
To install the JavaScript SDK, we’ll use the npm command. Open the terminal and run the following command:
Accessing the device microhpone, we can use navigator.mediaDevices.getUserMedia() method. The getUserMedia() method returns a Promise that resolves with a MediaStream object representing the captured media. We can then pass this MediaStream object to the SpeechSDK.AudioConfig object to create a SpeechSDK.AudioConfig object that represents the audio input device.
In above code, we are using the SpeechTranslationConfig object to configure the speech translation service. We are setting the outputFormat to Detailed to get the detailed translation result. We are setting the speechRecognitionLanguage to the original language and the addTargetLanguage to the target language. We are setting the SpeechServiceConnection_TranslationVoice property to en-US-JennyNeural to get the neural voice for the target language. We are creating a SpeechSDK.AudioConfig object from the MediaStream object and passing it to the SpeechSDK.TranslationRecognizer object, and setting the recognizing, recognized, and synthesizing event handlers to get the translation result.
The config.SPEECH_SUBSCRIPTION_KEY and config.SPEECH_SERVICE_REGION are the subscription key and region for the speech service. We are using these values to configure the speech translation service.
The recognizing event handler is called when the speech service is processing the audio input, and the recognized event handler is called when the speech service has recognized the speech input. The synthesizing event handler is called when the speech service is synthesizing the translated text to speech.
if (cancellation.reason === SpeechSDK.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.errorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } } };
constspeechSynthesizing = (s, e) => { var audioSize = e.result.audio === undefined ? 0 : e.result.audio.byteLength; var text =""; text += `(synthesizing) Reason: ${SpeechSDK.ResultReason[e.result.reason]}` + ` ${audioSize} bytes\r\n`;
if (e.result.audio && soundContext) { var source = soundContext.createBufferSource(); soundContext.decodeAudioData(e.result.audio, function (newBuffer) { source.buffer = newBuffer; source.connect(soundContext.destination); source.start(0); }); } }
In synthesizing event handler, we are logging the ResultReason and the audio size. If the audio property is not undefined, we are decoding the audio data and playing it using the Web Audio API.
The above soundContext is a global variable that we are using to play the audio. We can create the soundContext object using the AudioContext constructor. Below is the code to create the soundContext object.
Now, we can run the web application using the npm run dev command. Open the web browser and go to http://localhost:3000. You should see the web application with the microphone icon. Click the microphone icon to start recording the speech. Speak Chinese Mandarin, Cantonese speech voice and the web application will translate the speech to English language voice in real-time.
Speech Translator Demo
In above screenshot, it is recognize the speech to the text and we print it in console log. Once speech recognized. It is translated to English language voice and played in the web application.
Below are major code in index.js for Azure Speech Translator. It is simple to using Azure Speech Service to do the continous Speech Translation in real-time.
if (cancellation.reason === SpeechSDK.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.errorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } } };
constspeechSynthesizing = (s, e) => { var audioSize = e.result.audio === undefined ? 0 : e.result.audio.byteLength; var text =""; text += `(synthesizing) Reason: ${SpeechSDK.ResultReason[e.result.reason]}` + ` ${audioSize} bytes\r\n`;
if (e.result.audio && soundContext) { var source = soundContext.createBufferSource(); soundContext.decodeAudioData(e.result.audio, function (newBuffer) { source.buffer = newBuffer; source.connect(soundContext.destination); source.start(0); }); } }
The Speech Service of Azure AI is a cloud-based service that provides speech recognition and speech synthesis capabilities. It is a part of Azure AI suite. We can use it to build speech-enabled applications, such as speech-to-text, text-to-speech, and speech translation.